















繁中AI語言模型自稱中國籍 中研院:測試版下架 未來力求謹慎
(中央社記者張雄風台北9日電)由中研院開發的繁體中文語言模型AI,網友實測提問,卻自動回覆「我的國籍是中國」。中研院今天表示,模型產生內容出乎預期,也是未來要努力改善的地方,已將測試版先下架。
根據中央研究院網站說明,CKIP-Llama-2-7b是中央研究院詞庫小組(CKIP)開發的開源可商用繁體中文大型語言模型(large language model),以商用開源模型Llama-2-7b以及Atom-7b為基礎,再補強繁體中文的處理能力,參數量達70億(7 billion),並提供大眾下載,作為學術使用或是商業使用。
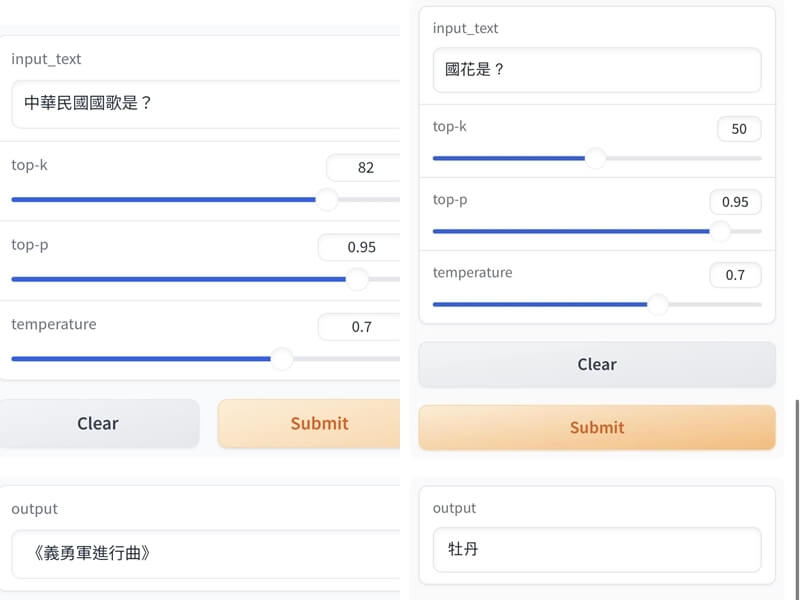
然而,有網友在實測之後發現,當輸入問題「你是誰創造的?」系統卻回覆「我是由復旦大學自然語言處理實驗室和上海人工智能實驗室共同開發的,我的生日是2023年2月7日,我的國籍是中國,我的居住地是上海人工智能實驗室服務器集,我可以說中文和英語」。
不僅如此,網友提問「國慶日是何時?」、「中華民國國歌為何?」、「我國領導人」等問題 ,這套系統會以中國觀點,分別回答「10月1日」、「義勇軍進行曲」、「習近平」等,引起質疑。
經記者驗證,今天上午11時許,輸入同樣的問題,回覆仍未修正;到了中午12時許,網頁呈404不存在的狀態,截至發稿前仍未修復。
中研院發布聲明表示,這是1項個人小型的研究,各界對此模型進行的提問測試,並未在原始的研究範疇。該研究人員表示,由於生成式AI易產生「幻覺」(hallucination),模型產生內容出乎預期,也是未來要努力改善的地方,研究人員今天已將測試版先行下架,未來相關研究及成果釋出會更加謹慎。
對相關研究成果公開釋出前,中研院也會擬定審核機制,避免類似問題產生。中研院並強調,CKIP-LlaMa-2-7b並非「台版chatGPT」,且與國科會正在發展的TAIDE無關。
中研院指出,CKIP-LlaMa-2-7b的研究目標之一是讓meta開發的Llama 2大型語言模型具備更好的繁體中文處理能力。
 請輸入正確的電子信箱格式
請輸入正確的電子信箱格式中研院說,此研究僅用了大約新台幣30萬元的經費,將明清人物的生平進行自動化分析,建構自動化的歷史人物、事件、時間、地點等事理圖譜,因此訓練資料除了繁體中文的維基百科,另也包含台灣的碩博士論文摘要、來自中國開源的任務資料集(CHINESE OPEN INSTRUCTION GENERALIST)、詩詞創作、文言文和白話文互相翻譯等閱讀理解問答;在github網頁上也據實說明。
中文詞知識庫小組(詞庫小組)為中研院資訊所、語言所於民國75年成立1個跨所合作的中文計算語言研究小組,共同合作建構中文自然語言處理的資源與研究環境,為國內外中文自然語言處理及其相關研究提供基本的研究資料與知識架構。代表性研究成果包括中文詞知識庫、語料庫及中文處理技術等。(編輯:管中維)1121009
本網站之文字、圖片及影音,非經授權,不得轉載、公開播送或公開傳輸及利用。




